
近日消息,中央广播电视总台大型公益节目 2024 年《开学第一课》播出,北京大学智能学院、人工智能研究院院长、计算机视觉专家、人工智能专家朱松纯教授携全球首个通用智能人 —— 小女孩(Little Girl)“通通”亮相节目现场。

据北京大学介绍,这位名叫“通通”的小女孩拥有三四岁的心智,是一个有“心”的人工智能。她所做的事情不受人为控制,而是由自己“心”里的价值所驱动。
在随机的场景中,“通通”会自主地捡起地上的玩具放进收纳盒中,拿起抹布擦去地上的污渍,搬起板凳清洗抹布。通过一系列的行为可以发现,“干净”是她的重要价值体系之一,这一切行为是通通在一百多个高度仿真的数字场景中,通过不断学习实现的技能、知识和价值的持续成长。
北京大学介绍称,与只能完成预定任务的智能体不同,培养“通通”这样一个具有自主感知、认知、决策学习、执行以及社会协作能力,同时符合人类情感伦理和道德观念的通用智能体,正是朱松纯教授的研究目标。
朱松纯解释称,鹦鹉学舌是通过重复训练实现的简单模仿,是一种低级智能;乌鸦喝水看似简单,却属于自主推理行为,是由价值与因果驱动的高级智能,也是人工智能的未来发展趋势。他借鉴中国传统哲学思想建立起原创性的以“理”(能力体系 U)与“心”(价值体系 V)双系统理论体系和“小数据 — 大任务”的发展新范式。
从北京大学官方获悉,朱松纯教授打造了我国唯一以“通用人工智能”命名的全国重点实验室 ——“跨媒体通用人工智能全国重点实验室”,探索通用人工智能新理论、新范式、新应用,成立“北京大学武汉人工智能研究院”,着力人工智能与人文社科深度交叉。
7月5日消息,“数字甲骨共创中心”于今日正式将全球最大的甲骨文多模态数据集开源,其中总共涵盖了一万片甲骨的拓片、摹本,还包括甲骨单字对应的位置、对应的字头、对应的释文以及辞例分组、释读顺序等数据。
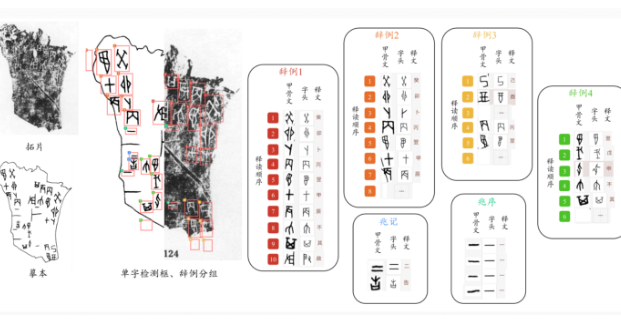
据介绍,所有研究者都能基于该数据集研发甲骨文检测、识别、摹本生成、字形匹配和释读等算法,加速甲骨文研究智能化进程。
数字甲骨共创中心由安阳师范学院甲骨文信息处理教育部实验室、腾讯 SSV 数字文化实验室、腾讯优图实验室、中国社会科学院甲骨学殷商史研究中心、中国社会科学院考古研究所安阳工作站、厦门大学多媒体可信感知与高效计算教育部重点实验室、郑州大学汉字文明研究中心等单位共同发起,并获得中国社会科学院古代史研究所、英国剑桥大学、法国高等研究实践学院、日本立命馆大学、美国罗格斯大学、加州大学洛杉矶分校等全球高校和研究机构的支持。
腾讯优图实验室、腾讯 SSV 数字文化实验室、厦门大学、安阳师范学院联合开发了 AI 模型技术:
甲骨字检测模型:标注准确率超 90%
摹本生成模型:摹本-拓片逐像素对齐
字形匹配模型:自动匹配相近字
甲骨校重模型:在大量拓片和摹本中实现“摹本去重”和“拓片探源”
全球最大甲骨文多模态数据集已在“甲骨文 AI 协同平台”上线,该平台还可以查询甲骨文、甲骨片信息,具体功能可以自行访问体验。
近年来,人工智能(AI)在编程能力方面持续取得进步,不过还未能达到尽善尽美的程度。近期,BuzzFeed的资深数据科学家Max Woolf经过实验发现,要是持续给大型语言模型(LLM)提供诸如“写出更优质代码”这类的提示,AI确实能够创造出质量更高的代码。

在 Woolf 的实验中,他利用 Claude3.5Sonnet 这一版本的 AI 模型进行了一系列编程任务。起初,他给模型提出了一个简单的编程问题:如何找出一百万个随机整数中,各位数之和为30的最小值与最大值之间的差。Claude 在接到这个任务后,生成了符合要求的代码,但 Woolf 认为该代码还有优化空间。
接着,Woolf 决定在每次生成代码后,都通过 “写更好代码” 的提示,要求 Claude 进行迭代优化。第一次迭代后,Claude 将代码重构为一个面向对象的 Python 类,并实现了两项显著的优化,运行速度提高了2.7倍。第二次迭代中,Claude 又加入了多线程处理和向量化计算,最终使得代码运行速度达到了基础版本的5.1倍。
然而,随着迭代次数的增加,代码质量的提升开始减缓。经过几轮优化后,尽管模型尝试使用一些更复杂的技术,例如 JIT 编译和异步编程,但有些迭代反而导致了性能的下降。最终,Woolf 的实验揭示了迭代提示的潜力与局限性,让人们对 AI 编程的未来有了新的思考。
这项研究不仅展示了 AI 在编程领域的应用潜力,也提醒我们,尽管 AI 能够通过不断迭代来提升代码质量,但在实际应用中,如何合理设计提示词、平衡性能与复杂性仍然是一个值得深入探讨的话题。
mobile3g.cn 版权所有 (C)2011 https://www.mobile3g.cn All Rights Reserved 渝ICP备20008086号-42


































